Prompt Optimization¶
Prompt engineering is often a manual, fragile trial-and-error process. Agentomatic solves this by providing a built-in Prompt Optimization Engine that acts like model.fit() but for your agent prompts.
Inspired by Stanford's DSPy, the framework allows you to evaluate agent performance over a dataset, automatically generate prompt candidates using a powerful rewriter model, score them using evaluation metrics, and export the best-performing prompt version back into your prompts.json file.
🏗️ The Optimization Flow¶
The optimization loop coordinates datasets, rewriter LLMs, evaluator LLMs, and scoring metrics to iteratively improve prompt versions:
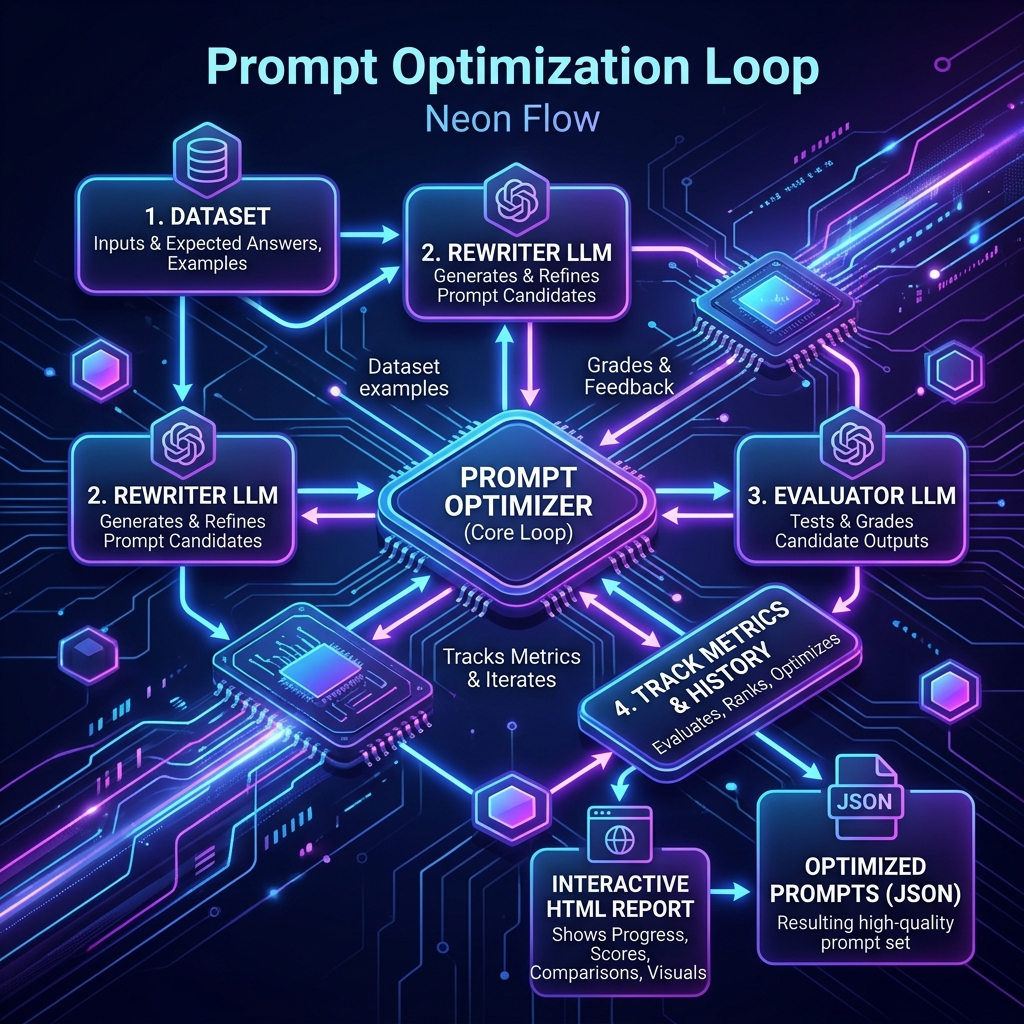
⚡ Quick Start¶
You can run prompt optimization programmatically in Python or with a single CLI command.
1. Programmatic Optimization (Python)¶
from agentomatic.optimize import PromptOptimizer, Dataset
# 1. Initialize the optimizer
optimizer = PromptOptimizer(
agent="my_agent",
metrics=["exact_match", "contains"],
strategy="iterative_rewrite",
)
# 2. Load the evaluation dataset
dataset = Dataset.from_jsonl("eval.jsonl")
# 3. Run the optimization loop
result = await optimizer.optimize(
dataset=dataset,
max_iterations=10,
target_score=0.9,
)
# 4. Print results & apply
print(result.report()) # Terminal report summary
result.apply() # Saves the optimized prompt as a new version in prompts.json
2. CLI Command¶
agentomatic optimize my_agent \
--dataset eval.jsonl \
--metrics exact_match,contains \
--strategy iterative_rewrite \
--max-iterations 10 \
--apply
🧠 Optimization Strategies¶
Agentomatic supports 6 optimization strategies suited for different task formats and complexities:
| Strategy Name | CLI / String ID | How It Works | Best Used For |
|---|---|---|---|
| Iterative Rewrite | iterative_rewrite |
Evaluates prompts, feeds errors/scores to a powerful rewriter LLM, and refines instructions iteratively. | General instruction-following and system prompt refinement. |
| Few-Shot Bootstrap | few_shot_bootstrap |
Runs the agent over the dataset, collects high-scoring successful traces, and bootstraps them into the prompt as examples. | Complex logic requiring demonstration of correct formatting/reasoning. |
| Chain of Thought | chain_of_thought |
Rewrites the prompt to enforce step-by-step reasoning instructions and generates visual scratchpad examples. | Multi-step reasoning and mathematical/logical problems. |
| MIPRO | mipro |
Bayesian-based prompt optimizer. Jointly optimizes both the instruction strings and few-shot examples using search space trials. | High-complexity pipelines where both instructions and examples matter. |
| Bootstrap Random Search | bootstrap_randomsearch |
Bootstraps multiple few-shot example sets and runs a random search to find the optimal examples for the prompt. | Large datasets where handpicking examples is impossible. |
| Ensemble | ensemble |
Evaluates and compiles multiple high-performing prompt variants into a weighted ensemble prompt. | Robust prompt engineering requiring high generalization. |
📊 Evaluation Metrics¶
Agentomatic supports standard matches, LLM judges, and full DeepEval validation suites.
1. Text Matching Metrics¶
- Exact Match (
exact_match): Verifies if the agent response matches the expected answer exactly. - Contains (
contains): Verifies if the agent response contains a set of defined target keywords.
2. LLM-as-a-Judge Metrics¶
- LLM Judge (
llm_judge): Asks an evaluator LLM to grade the response on a scale of 0 to 1 based on custom criteria instructions. - G-Eval (
g_eval): Uses the G-Eval framework protocol to evaluate complex criteria (e.g. coherence, readability) with detailed scoring rubrics.
3. DeepEval Metrics (deepeval)¶
Requires pip install agentomatic[optimize]. Integrates directly with the Confident AI DeepEval framework:
- Answer Relevancy (answer_relevancy): Measures how relevant the agent response is to the user query.
- Faithfulness (faithfulness): Evaluates Hallucination by comparing the agent response to retrieved context.
- Context Recall (context_recall): Measures whether the RAG retriever fetched all the required context.
4. Custom Metrics (Python)¶
You can define any custom Python function returning a score between 0.0 (worst) and 1.0 (best):
from agentomatic.optimize import CustomMetric
def check_word_count(response: str, expected: str, **kwargs) -> float:
# Reward responses under 100 words
words = len(response.split())
return 1.0 if words < 100 else 0.0
metric = CustomMetric(name="short_answers", scorer=check_word_count)
optimizer = PromptOptimizer(
agent="my_agent",
metrics=[metric],
strategy="iterative_rewrite",
)
🗄️ Loading Datasets¶
The Dataset loader accepts JSONL, CSV, or raw Python dictionaries:
🧪 Synthetic Data Generation¶
If you don't have a dataset, Agentomatic's DataSynthesizer can auto-generate high-quality evaluation sets from a textual description or from raw text files (e.g. employee handbooks, text documentation):
from agentomatic.optimize import DataSynthesizer
synth = DataSynthesizer(model="ollama/llama3:8b")
# Generate 50 test cases covering specific categories
dataset = await synth.generate(
description="Customer support assistant answering questions about orders and returns",
n_samples=50,
categories=["returns", "shipping", "refunds"],
)
# Save to disk
dataset.to_jsonl("synthetic_eval.jsonl")
To generate directly from local text files or markdown files:
from agentomatic.optimize import generate_from_docs
dataset = await generate_from_docs(
docs_path="docs/handbook.txt",
model="ollama/llama3:8b",
n_samples=30,
)
🛡️ Red Teaming (Adversarial Testing)¶
Run red-team evaluations to test your agents against adversarial inputs, prompt injections, and toxic prompts:
from agentomatic.optimize import red_team, RedTeamMetric
# Generate 20 adversarial prompts targeting prompt injection and jailbreaks
adversarial_dataset = await red_team(
agent_name="my_agent",
categories=["prompt_injection", "pii_leakage", "toxicity"],
n_samples=20,
)
# Optimize system instructions to resist these vulnerabilities
optimizer = PromptOptimizer(
agent="my_agent",
metrics=[RedTeamMetric(vulnerability="prompt_injection")],
strategy="iterative_rewrite",
)
result = await optimizer.optimize(dataset=adversarial_dataset, max_iterations=5)
result.apply()
📊 Interactive HTML Reports¶
Every optimization run generates a rich, interactive HTML report comparing prompt versions side-by-side. The report includes: - Latencies and Durations: Graphing execution times. - Metric Scores: Side-by-side score comparison bars. - Prompt Diff Viewer: Clean GitHub-style diff showing exactly what instructions were added/removed. - Trial Traces: Full message logs, reasoning steps, and tool calls for every test case.